DB2 – Data Compression
1. Overview of Compression
테이블 단위의 데이터 압축을 위해서는 다음 두 가지 사항이 필요합니다.
첫째, 테이블 생성(Create) 또는 수정(Alter)을 통해 COMPRESS YES 절을 명시하여 압축이 가능하다는 표시를 해주어야 합니다.
둘째, 테이블에 들어있는 데이터에 대한 압축 사전이 정의 되어야 합니다.
위 두 가지 조건이 만족되었을 경우 테이블에 데이터가 추가(Insert) 및 갱신(Update) 될 때 데이터 압축이 이루어지게 됩니다.
각각의 테이블에 대해서 압축 사전이 만들어 지게 되는데, 이 압축 사전은 범위지정(Range) 테이블의 파티션이나 DPF 상의 파티션에도 따로 존재하게 됩니다.
가. Building the compression dictionary
DB2 제품의 릴리즈 레벨이나 버전 레벨에 따라 압축 사전을 만드는 방법이 다릅니다.
l DB2 Version 9.1 : 첫 번째 방법은 테이블에 대해 Reorg 명령을 발행하는 것입니다. 압축 사전은 REORG TABLE 문의 RESETDICTIONARY 나 KEEPDICTIONARY 옵션을 통해 만들어 지거나 관리됩니다. 두 번째 방법은 INSPECT 유틸리티를 사용하는 것입니다.
l DB2 Version 9.5 : 테이블 Reorg 와 INSPECT 명령 뿐 아니라 테이블의 증가 정도에 따라서 자동으로 데이터 압축 사전을 만들 수 있습니다(ADC(Automatic Dictionary Creation) 트리거에 의해 동작됨). 압축 사전은 LOAD REPLACE 시 RESETDICTIONARY 와 KEEPDICTIONARY 옵션을 통해 관리됩니다.
2. Choosing candidate tables for compression
테이블 압축은 데이터 증가로 인한 스토리지 사용량을 줄여 주는 스토리지 최적화 기술입니다.
일반적으로는 용량이 큰 테이블에 대해 압축을 적용하는 것이 몇 백, 몇 천 건의 데이터를 가지는 테이블을 압축할 때 보다 얻을 수 있는 기대 효과가 높습니다.
다음의 예와 같이 ADMIN_GET_TAB_INFO 라는 SQL 관리 함수를 이용하게 되면 특정 스키마에 속한 모든 테이블에 대한 테이블 오브젝트 크기를 구할 수 있습니다.
|
SELECT TABNAME, DATA_OBJECT_P_SIZE FROM
TABLE(SYSPROC.ADMIN_GET_TAB_INFO(‘schema_name’,’’) AS T
ORDER BY DATA_OBJECT_P_SIZE
|
위 함수를 이용한다면 압축을 수행한 테이블에 대한 압축 사전의 크기를 얻어 올 수 있어 실제로 테이블의 디스크 사용량이 줄어 들게 되는 양을 확인 할 수 있습니다. 만일 DICTIONARY_SIZE 값이 NULL 인 경우는, 특정 데이터 파티션에 대해서 압축 사전을 가지고 있지 않거나, 테이블에 데이터가 들어 있지 않아서 압축을 수행할 수 없는 상태 입니다.
데이터 건수가 많지 않은 테이블에(실제 크기가 몇 백 KB) 대해서 압축을 수행할 경우에는 오히려 압축 사전을 만들 때 필요로 하는 디스크 공간 때문에 실제 사용량이 늘어 날 수도 있습니다.
데이터 압축을 적용하고자 한다면 테이블의 크기가 1MB 보다 큰 테이블을 대상으로 선정하는 것이 좋습니다.
SQL 조작 특성을 통해서 데이터 압축을 적용할 테이블을 선정할 수 있습니다. Read-only 테이블인 경우와, Update 가 빈번히 발생하는 테이블, 일기/쓰기 비율이 70/30 정도로 읽기 호출이 빈번한 테이블에 대해서는 압축을 적용하는 것이 벤치마킹의 결과가 좋게 나왔습니다.
OLTP 환경에서는 테이블에 대한 데이터 압축을 수행할 경우 동일한 데이터에 대해서 비 압축 시 보다 읽어야 하는 페이지의 양이 줄어 들 뿐 아니라 버퍼 풀 적중률도 높아져 성능의 향상을 가져옵니다.
행 압축을 사용할 시 I/O 바운드는 줄어 들게 되지만, 오히려 압축 및 압축 해제 시 CPU의 사용은 증가하게 됩니다. 이 부분은 DW 같은 복잡한 SQL이 수행되는 경우 오히려 I/O 성능 개선을 통해 워크로드가 줄어드는 것에서 이점을 찾을 수 있습니다.
압축을 통해서 향상되는 것으로는 INSERT, UPDATE, DELETE 시 사용되는 Log 사용량이 줄어든다는 것도 있습니다. Log 사용량을 줄어 들면서 컬럼 update 처리가 효율이 높아 지게 됩니다.
3. Estimating compression ratios
DB2 V9부터는 INSPECT ROWCOMPESTIMATE 유틸리티를 통해 테이블의 데이터를 압축하기 전에 스토리지 사용량이 어느 정도 절감되는지 확인을 할 수 있습니다.
INSPRECT 명령에 ROWCOMPESTIMATE 절을 사용하여 명령을 실행 할 경우 해당 테이블에 대한 압축 사전이 만들어 지면서 스토리지 절감에 대한 내용이 보고서 형태의 파일로 저장됩니다.
만일, 테이블에 COMPRESS YES 옵션이 지정되지 않았을 경우에도 실제 압축은 수행되지 않지만 스토리지 절감에 대한 결과 파일은 확인 할 수 있습니다. 테이블에 COMPRESS YES 옵션이 지정되어 있지만 데이터 압축이 수행되지 않았을 경우에는 INSPRECT 명령이 수행되면서 압축 사전이 만들어 지게 됩니다.
테이블의 압축률을 알아 보기 위한 명령 실행 순서 입니다.
1. INSPECT 명령 수행
|
db2 INSPECT ROWCOMPESTIMATE TABLE NAME table_name SCHEMA schema_name RESULTS
KEEP file_name
|
INSPECT 명령을 통해 나오는 결과 파일은 DBM CFG의 DIGPATH에 설정된 경로에 생성됩니다.
2. 결과 파일 변환
|
db2inspf file_name output_file_name
|
db2inspf 명령을 통해서 INSPECT 명령을 통해 생성된 바이너리 파일을 텍스트 형태의 파일로 컨버전을 해 줍니다.
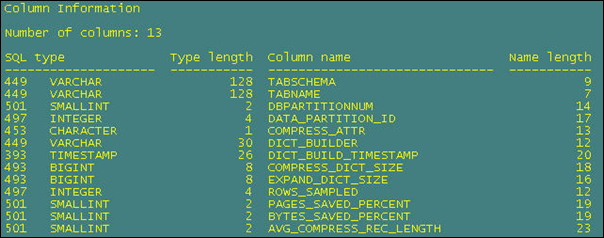
다음은 컨버전을 통해 본 결과 파일의 예시입니다.

DB2 V9.5 에서는 SQL 관리 함수인 ADMIN_GET_TAB_COMPRESS_INFO를 통해서 데이터 압축률을 확인 할 수 있습니다.
|
SELECT * FROM TABLE(SYSPROC.AMDIN_GET_TAB_COMPRESS_INFO (‘schema’,
‘table_name’, ‘mode’)) AS T
|
위와 같은 SQL 문을 수행하면 되며, mode 값은 ‘REPORT’ 또는 ‘ESTIMATE’ 입니다.
‘ESTIMATE’ 모드를 사용하는 경우는 ROWCOMPESTIMATE 옵션을 사용한 INSPECT 유틸리티의 결과와 비슷하게 출력이 됩니다. SQL 관리 함수를 사용할 경우는 반드시 RUNSTATS 명령을 수행해야 정확한 결과 값을 확인 할 수 있습니다.
‘REPORT’ 모드를 사용하는 경우는 압축 사전의 생성 정보를 확인 할 수 있습니다. 압축 사전이 빌드된 시간, 압축을 통해 절약된 페이지 수 등의 정보를 확인할 수 있습니다.
테이블스페이스 디자인 시 테이블스페이스 형태를 REGULAR로 할 경우 페이지당 최대 row 수가 255개로 제한이 됩니다. 데이터 압축을 적용할 시 한 페이지에 255보다 많은 수의 row가 들어가도록 하기 위해서는 LARGE 타입의 테이블스페이스를 권장합니다.(DB2 V9부터는 DMS 테이블스페이스의 디폴트 타입은 LARGE 입니다. SMS의 경우는 REGULAR)
|